| Back | Return to Beginning | Next |
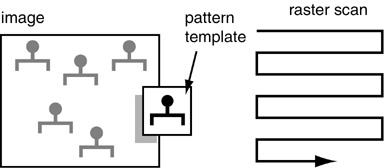
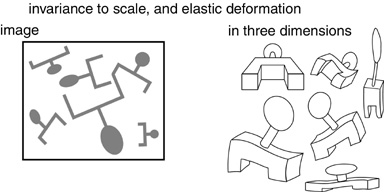
The issue of invariance is even more challenging in visual perception, where simple shapes are recognized independent of their rotation, translation, and scale, as well as of elastic deformations. If spatial patterns are detected by any kind of spatial template, then that templates would have to be tested at every point across the visual field. In computer simulations this is usually done by scanning the template at every location cross the image. In neural network models the template is generally replicated at every location across the image, to perform the search in parallel.
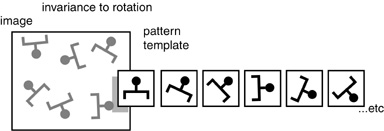
If recognition is to be invariant to rotation, then the template must be scanned (or replicated) at every orientation at every spatial location.
| Back | Return to Beginning | Next |