Steven Lehar
Submitted to Perception
Rejected October 1996
The phenomena of brightness contrast and brightness constancy have been addressed by models which propose a low-level center-surround interaction occurring early in the visual system. Studies by Gelb (1929), Gilchrist (1977, 1983) Knill (1991) and Adelson (1993) have shown that the perception of surface brightness is also influenced by factors such as the perceived illumination and the perceived three-dimensional configuration of the perceived object. Adelson suggests that such complex interactions must occur later in the visual system suggesting a cognitive accompaniment to low level perception. These influences are however not accessible to conscious analysis and appear automatic and pre-attentive, which suggests a low level processing. I propose that the perception of lightness, brightness, perceived illumination, and three dimensional form are all low level phenomena which occur early in the visual processing by a parallel Gestalt relaxation in a fully spatial representation.
Over the past decades psychophysical evidence has been accumulating which suggests complex interactions between the perception of lightness, brightness, illuminance, and three dimensional form. Individual researchers have tended to specialize in one or two of these perceptual modalities in isolation, on the assumption that the individual aspects of perception are computed in separate low level brain areas, to be integrated into a coherent percept at a higher level integrating stage. This modular hierarchical organization is indeed what is suggested by the neurophysiological architecture of the visual cortex, and is characteristic of modular processing algorithms proposed in computer vision.
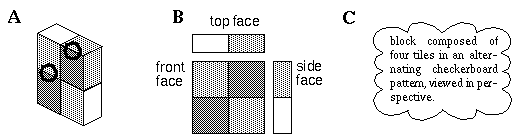
The Gestalt principles of perceptual organization suggest an alternative, more parallel processing architecture. According to Gestalt principles, the low level percept of local features is influenced by the higher level global configuration. The block shown in Figure 1 (A) (from Adelson 1993) illustrates the interaction between brightness and form perception. The two circled edges separate regions of exactly the same shades of darker and lighter gray, but because of the global gestalt, one edge is perceived as a reflectance edge on a plane surface, while the other is perceived as an illuminance edge due to a corner, with no change in surface reflectance. This appears to be a low level percept since the two edges appear phenomenally very different, even when one is cognitively aware of the fact that they are locally identical. An algorithm which made decisions on a local basis would categorize these two edges as identical. The Gestalt principles suggest that perceptual processing does not proceed in a sequential feed-forward manner through successive processing stages, nor do the individual computational modules operate independently. Instead, Gestalt theory suggests that all perceptual modules operate in parallel, both at the local and the global level, and the final percept is the result of a relaxation which emerges in a manner that is most consistent with all of the multiple interconnected modules. This idea is not inconsistent with the modular architecture revealed by neurophysiology as long as the individual modules are presumed to be tightly coupled with one another in such a way that a perceptual constraint detected in any one module is simultaneously communicated to every other module. For example the pre-attentive perception of three-dimensional structure in Figure 1 (C) constrains the circled edges to appear as a plane and a corner in depth respectively, and this in turn influences the low level perception of lightness and at those points. A close coupling across widely separated brain areas has been identified neurophysiologically in the form of synchronous oscillations (Eckhorn 1988). The challenge for modeling of the perceptual process is that the individual modules must be designed so as to receive information both bottom-up from sensory input, top-down from global processing modules, as well as laterally from parallel parts of the data stream. This type of parallel accumulation of evidence from multiple sources appears counter to the scientific tendency to divide the problem into separate and independent components, and requires novel concepts in computational principles. In particular it requires the perceptual mechanism to be defined as a multi-stable dynamic system (Attneave 1971) whose stable states are sculpted by the configuration of the input, and whose individual modules are coupled so as to produce a single globally coherent perceptual state. A model with the required properties will be of necessity rather complex, with dynamic properties that will be difficult to characterize with precision. The purpose of this paper therefore is not so much to present an exact computational algorithm, but rather to suggest a general computational strategy based on the Gestalt principles, for computing lightness, brightness, perceived illumination, and three dimensional form in a single low level computational mechanism by way of relaxation in a multi-stable dynamic system.
(A) Illustration (from Adelson 1993) showing how the perceived three-dimensional structure influences the local brightness percept in an image. (B) The same spatial information as in (A), but requiring cognitive inference for its spatial integration. (C) A high level cognitive description of the block in (A). block composed of four tiles in an alternating checkerboard pattern, viewed in perspective.
1.1 High Level v.s. Low Level Representation
Central to this discussion is the distinction between high level and low level processing. Adelson (1993) assumes that the influence of perceived spatial structure on the perception of surface brightness shown in Figure 1 (A) reflects a high level or cognitive influence on a low level percept. This assumption is consistent with the conventional view of visual processing embodied in models such as Marr's Vision (1982) and Biederman's Geon theory (1987), which reflect the current consensus on the nature of visual processing. In these models the lower levels extract simple local features such as edges, higher levels extract spatial combinations of edges, detecting such features as long continuous edges, or corners and vertices, and higher levels still extract two-dimensional enclosed surfaces defined by bounding edges and vertices. The highest levels combine information from configurations of such surfaces in order to infer the three-dimensional structure of the scene. Characteristic of this kind of processing progression are the principles of abstraction, compression, and invariance.
Abstraction represents a many-to-one combination of alternative sensory features. For example a visual edge may be defined as a dark/light or a light/dark edge in a contrast sensitive representation, whereas a contrast- insensitive representation makes no distinction based on contrast polarity, and thus represents a more abstract, or high level representation in the sense that it is farther from the representation seen in the visual input. Indeed lower level simple cells are contrast sensitive, while the relatively higher level complex cells are not (Hubel 1988).
Information compression is also a many-to-one relationship between a more expanded low level representation and a more compressed high level one. Attneave (1954) proposes that information compression is an essential property of visual processing in order to reduce to manageable proportions the overwhelming complexity of the visual input. Indeed the transformation from a contrast-sensitive to a contrast-insensitive representation also performs compression since every contrast-insensitive edge corresponds to two contrast-sensitive edges of opposite contrast polarity. The retinal transformation from a surface brightness image detected by retinal cones to an edge based image of the retinal ganglion cells can also be seen as information compression, since the edge image encodes only the changes at the boundaries of the luminance image.
Invariance is the property of a high level representation with respect to transformations of the low level input. For example a "node" in the brain representing a square would be invariant to perspective transformation if it were active whenever a square was present in the input, independent of its rotation, translation, or scale. This again represents a many-to-one relationship between the invariant concept and its various possible manifestations, and thus represents also both abstraction and compression.
The three principles of abstraction, compression, and invariance are therefore intimately connected, and appear to characterize the nature of a high level representation with respect to its lower level counterpart. Other characteristics associated with a low level percept are a high spatial resolution, since the primary visual cortex has a higher resolution in millimeters of cortex per degree of visual angle than higher cortical areas, and a pre- attentive nature since the lower levels of visual representation are unavailable to conscious influence, i.e. high level inferences can be made from a low level percept, but those inferences do not change the immediate spatial experience of that percept which is determined exclusively by the state of the lower levels of the representation.
Based on these characteristics of high v.s. low level representations I would argue therefore that contrary to the conventional view of perception as embodied in the models of Marr (1982) and Biederman (1987), the perception of three-dimensional structure as seen in Figure 1 (A) is a low level percept rather than a high level cognitive inference. This is evidenced by the fact that the spatial aspect of this percept is pre-attentive, is seen at the highest spatial resolution, and exhibits properties which are the inverse of abstraction, compression, and invariance, i.e. the percept is reified, uncompressed, and variant. Figure 1 (B) illustrates a three-view schematic representation of that same block depicted in Figure 1 (A). In this case the third dimension is not perceived directly, but is indeed inferred cognitively from the two-dimensional surfaces in the image, as suggested by Marr and Biederman. The nature of this percept however is qualitatively different from that due to Figure 1 (A), although the spatial information encoded in the figure is virtually identical. The information about the reflectance of the component tiles of the block and direction of the illumination source, which "pop out" pre-attentively from Figure 1 (A) must be cognitively calculated in Figure 1 (B). Furthermore, the spatial information evident in Figure 1 (A) is so complete, it is easy to hold the flat of your palm parallel to any of the three depicted surfaces, as if viewing an actual block in three-dimensions, without any conscious awareness of how this task is performed. This is in contrast to the verbal or symbolic description of the block depicted in Figure 1 (C) which is abstracted, compressed, and invariant to perspective transformation; i.e. there are many different possible depictions such as Figure 1 (A) all of which correspond to the single invariant description shown in Figure 1 (C). The influence of the spatial percept on the perception of brightness and lightness of surfaces in the figure is therefore not in the nature of a top-down inference as suggested by Adelson (1993) but rather of a lateral influence from one low level module to another.
1.2 Abstraction v.s. Reification
The above observations about the characteristics of higher v.s. lower level representations lead to some radical conclusions about the nature of visual processing which are contrary to the conventional feed-forward hierarchical processing concept. Consider the Kanizsa figure, depicted in Figure 2 (A). It has been argued (Kennedy 1987) that the illusory contour observed in this figure represents a higher level representation or quasi- cognitive inference based on the lower level visual edges which induce it. This argument is based presumably on the fact that the illusory contour is calculated on the basis of the visible stimulus, and thus must be represented "downstream" in the processing hierarchy, which in the conventional view means at a higher representational level. The inducers directly responsible for this figure however consist of local contrast-sensitive edges at the straight segments of the pac-man figures. There are two components to the percept induced by this figure; there is a higher level abstract recognition of a triangular relationship, as is seen also in Figure 2 (B), where the perceived triangular grouping is seen without any brightness percept. But in Figure 2 (A) there is in addition an accompanying low level percept which consists of a visible contrast sensitive edge which is virtually indistinguishable from an actual luminance edge, as well as a percept of surface brightness which fills in the entire triangular figure with a white that is apparently whiter than the white background of the figure. In other words in this illusion, visual edges in the stimulus are seen to produce a surface brightness percept, which suggests a high level representation generating a lower level one. Furthermore, the pac-man features are not perceived as segmented circles, but are seen as complete circles which are completed amodally behind an occluding triangle. The information represented in this illusory percept therefore is something like that depicted in Figure 2 (C), i.e. a three-dimensional percept of a foreground bright triangle occluding three black circles on a slightly darker background. This percept has the characteristics of a low level representation because it is seen pre-attentively, at high spatial resolution, and with a specific contrast polarity. What is interesting about this and similar illusory figures is that they reveal the fact that the visual system performs the inverse of abstraction, or reification, i.e. a filling-in of a more complete and concrete representation from a less complete, more abstracted one. This immediately raises the issue whether such reification is actually performed explicitly by the visual system, or whether reification is a subjective manifestation without neurophysiological counterpart.
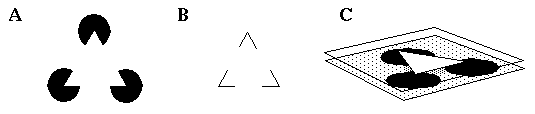
(A) The Kanizsa figure. (B) The high level triangular relationship which is a component of the percept in (A). (C) The information present in the percept due to (A).
1.3 The Gestalt Principle of Isomorphism
The Gestalt principle of isomorphism, elaborated by Wolfgang Köhler (1947), suggests an answer to this question. Köhler argued that the nature of the internal representation can be deduced directly by inspection of the subjective percept. Consider a stimulus of a white square on a black background, as shown in Figure 3 (A). The retinal image in response to this stimulus is a contrast-sensitive edge representation, like the one shown schematically in Figure 3 (B), where the light shading represents active "on" cells and the dark shading represents active "off" cells, and the neutral gray represents zero activation of either cell type. The subjective percept in response to this stimulus however is not of an edge image, but of a solid filled-in percept, as shown in Figure 3 (C). It has been argued (Dennett 1991) that the internal cortical representation of this stimulus need not explicitly fill-in the brightness percept because the information required for such filling-in is already implicitly present in the representation. This however would represent a violation of the principle of isomorphism, because the edge representation shown in Figure 3 (B) is not isomorphic with the surface brightness representation shown in Figure 3 (C), i.e. there is no cell or variable in the representation of Figure 3 (B) which indicates the white percept at the center of the square. Köhler argues that such a model cannot be said to model the percept at all, because there is no way to verify whether the internal representation accurately predicts the nature of the subjective percept. In an isomorphic model there must be some cell or variable or quantity at the center of the square which is "on" when a whiteness is perceived at that location, and "off" when no whiteness is perceived there. Note that the cell itself need not actually "turn white" to represent a perception of white, it need only be labeled "white"; i.e. the principle of isomorphism does not extend to the physical implementation of the representation, but merely to the information represented therein. In other words a procedure must be defined to determine from the values in the internal representation what the predicted subjective percept must be. In the absence of such an isomorphic relation, Köhler argues, one would have to invoke a kind of dualism to account for the difference in informational content between the internal representation and its corresponding percept. Stated in the form of a reductio ad absurdum, if it were sufficient for the internal representation to encode perceptual information only implicitly, then there would be no need to postulate any further cortical processing, because the retinal image itself already contains implicitly all the information manifest in the subjective percept.

(A) An example visual input. (B) The corresponding retinal representation, where light tones represent the response of on-center cells, and dark tones represent the response of off-center cells, while the neutral gray represent no response from either cell type. (C) The subjective percept when viewing (A).
1.4 Perceptual Modeling v.s. Neural Modeling
The argument of isomorphism extends equally to spatial percepts such as that in Figure 1 (A), which appears almost as if made out of cardboard in three-dimensions. Whatever the actual internal representation of this three- dimensional percept, the principle of isomorphism states that the information encoded in that representation must be equivalent to the spatial information encoded in the cardboard model of the percept, i.e. with a continuous mapping in depth of every point on every visible surface. Models of spatial perception however very rarely allow for such an explicit representation of depth. Marr's 21/2-D sketch (Marr 1982) for example encodes the spatial percept as a two-dimensional map of surface orientations, like an array of needles pointing normal to the perceived surface. Koenderink (Koenderink 1976, 1980, 1982) proposes a nominal representation where each point in the two-dimensional map is labeled as either elliptic, hyperbolic, or parabolic. Todd (1989) proposes an ordinal map where each point in the two-dimensional map records the order relations of depth and/or orientation among neighboring surface regions. Grossberg (Grossberg 1987a, 1987b) proposes a depth mapping based on disparity between two-dimensional left and right eye maps. None of these compressed representations are isomorphic with our subjective perception of a full volumetric depth world. The gap between our subjective perception of space and our knowledge of the neurophysiological representation of space seems so great that it seems impossible to bridge using currently accepted concepts of neural interaction. In the current intellectual climate the response to this dichotomy has been to ignore the conscious percept and to model only known physiology. This is in contrast to the Gestalt view of perception, which by the principle of isomorphism considers the subjective conscious experience as a valid source of evidence for the nature of the internal representation. In the absence of complete knowledge of neurocomputational principles and representations, a safer approach would be to perform perceptual modeling as opposed to neural modeling, i.e. model the percept as observed, rather than the neurophysiological mechanism by which it is subserved. This approach must eventually either converge with known neurophysiological knowledge, or (in my view more likely), it will highlight areas where novel computational principles and mechanisms remain to be discovered neurophysiologically. Indeed a purely neural modeling approach would preclude ever discovering novel computational principles through psychophysics, i.e. neural modeling restricts itself to currently accepted neurocomputational principles, whereas by perceptual modeling we can allow perceptual phenomena to drive the search for neurophysiological mechanisms, at the same time that neurophysiological data drives the perceptual models.
1.5 The Illusion of Consciousness?
An objection may be raised as to the validity of perceptual modeling, in that conscious perception may be an illusion, giving an impression of more information being represented than is actually encoded internally. The classical example is the reduced retinal resolution in peripheral vision, which is a fact of perception of which the naďve observer is not consciously aware. Another more startling example was demonstrated recently by Rensink (1995). He presented subjects with videotaped pictures of static natural scenes, for example a static view of a kitchen scene, and at some point a major component of the scene suddenly disappears; for example the camera is paused while the refrigerator is removed, producing a magical disappearance effect. Rensink showed that if the moment of disappearance is masked by splicing a few milliseconds of a random noise pattern into the videotape, subjects were often unaware of the phenomenal disappearance, i.e. they were not able to identify the difference between the before and after scenes. This experiment suggests that the internal representation of a visual scene is far simpler than the conscious experience of it would suggest.
This objection will be addressed as follows: in the first place, the resolution loss in peripheral vision, while invisible to the naďve observer, is clearly manifest to a carefully trained observer, and measurable using a simple acuity test; i.e. perceptual modeling should be based on conscious perception as observed critically, or as measured objectively in psychophysical tests. Secondly, it is far easier to demonstrate a failure of perception, as shown by Rensink, than it is to demonstrate the information accurately assimilated in perception. There is a pathological tendency in visual modeling circles to attempt to minimize the complexity of the vision problem in order to simplify the effort required to model it. This tendency in my view accounts for the attention received by experiments such as Rensink's, because they confirm the validity of simplistic models while casting doubt on the subjective conscious experience, a view that confirms the current conventional wisdom in perception. The conceptual problem with this approach is that the measured complexity or sophistication of perception is always limited by the nature of the experiment that measures it. For example a detection threshold experiment suggests a simple model of vision as a mechanical photosensor with stochastic properties. Since only a simple aspect of perception is tested, a simple model is sufficient to account for the data. The problem of visual perception however should not be to model the simplest measurable phenomena, but rather to account for the most complex and subtle visual behavior demonstrated by the organism in its natural environment. Indeed this is the very objection raised by both Gibson and the Gestaltists in response to the simplistic experiments of the behaviorists, and their correspondingly simplistic models of cognition. It is easy, for example, to model the looming reaction of the house fly, whereby tethered flies presented with an expanding pattern of dots exhibit a landing response. It is far more difficult to account for the visual performance of a fly dodging between the branches of a tangled shrub in dappled sunlight in a gusty crosswind. A model of the former is trivial, but meaningless to the big issues of perception, whereas modeling the latter is well beyond current theoretical understanding.
While I do not dispute Rensink's findings, and recognize that this aspect of perception must be incorporated in a complete model of perception, equal emphasis should be given to a counter-experiment which might proceed as follows: architectural students trained in building three-dimensional painted cardboard models should be shown the videotape of the static kitchen scene for the same duration as Rensink's subjects, and instructed after viewing to construct from memory a complete spatial model of the kitchen. The emphasis in this experiment would be to measure what is captured, rather than what is missed by visual perception, and the outcome would almost certainly show that the subject's spatial perception abilities are far beyond the ability of any current model of perception to begin to explain. This result however would be so obvious that the experiment need hardly be conducted. The fact that visual perception sometimes misses prominent objects in the scene is by no means as significant as the fact that it usually captures the essential structure of a scene, converting a complex two- dimensional input into a still more complex three-dimensional spatial percept. It is this remarkable performance of the visual system which requires explaining by models of perception.
I will now develop a perceptual model of the phenomenon of brightness perception based on the Gestalt principles of global emergent properties from local interactions by relaxation in a multi-stable dynamic system. The model will take into account the influence of the perceived illumination as well as the perceived three- dimensional form, all computed as low-level interactions. Since the scope of this model, i.e. the breadth of data that it is designed to explain, is considerably greater than that normally addressed by such models, this model will of necessity be somewhat sketchy, and many details will remain to be defined. The intention therefore is not so much to present an exact model of perception, as to propose a general approach to computational modeling which is consistent with the general Gestalt view of perception.
The model will be developed in an evolutionary progression, beginning with a simple model to explain one aspect of perception, with additional features and mechanisms being added to account for ever more properties of perception. I will begin with a model of brightness constancy and brightness contrast, then add the influence of the perceived illumination, then develop a low level mechanism for the perception of three-dimensional form, with mechanisms to handle the perception of the three-dimensional illumination profile, and show how this model now also explains the perception of transparency, neon color spreading, as well as shape from shading, and the perception of attached shadows and cast shadows. I hope to show by example that the mechanism of perception will never be adequately explained using the conventional piecemeal approach, but that the problem of perception must be approached in its entirety in order to achieve a model which captures the essential principles of natural vision.
2.1 Brightness Contrast and Brightness Constancy

(A) The brightness contrast illusion. (B) The presumed retinal stimulus pattern while viewing (A).
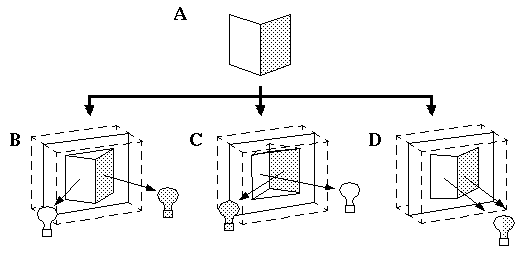
The phenomenon of brightness contrast, illustrated in Figure 4 (A) shows that the perceived brightness of a patch is influenced by the brightness of the surrounding region in a manner that appears to increase the contrast against the background, i.e. the gray patch on the black ground is seen as brighter than the gray patch on the white ground. This effect has been explained by lateral inhibition of the sort thought to operate in the retina, whereby cells with an on-center off-surround receptive field respond on the bright side of a contrast edge, while cells with an off-center on-surround receptive field respond on the dark side of the same edge. Figure 4 (B) illustrates schematically the retinal response to the stimulus in Figure 4 (A), with white regions representing the response of "on" cells, and dark regions representing the response of "off" cells, while the neutral gray regions represent no response from either cell type. While this kind of model has been proposed to explain the contrast effect, the response shown in Figure 4 (B) is not isomorphic with the percept while viewing Figure 4 (A), since it is an edge representation rather than a surface brightness representation. Indeed it is hard to say from Figure 4 (B) exactly what the corresponding brightness percept should be. Furthermore, if Figure 4 (B) reflects the internal representation when viewing Figure 4 (A), what would the internal representation be when viewing Figure 4 (B)? Land (1977) proposed an analytic model to explain the perception of brightness (and perceived color) as a function of different colored surrounding regions, by integrating the differences across all of the edges between the patches under comparison. Land's model did not however generalize to arbitrary shaped regions, and was proposed only to fit certain psychophysical data, rather than as a model of the mechanism of brightness perception. Similarly Arend (1973) proposed a model of brightness perception which involved a spatial derivative followed by a spatial integral. This model was defined in terms of a one-dimensional path through the two-dimensional image, and thus also fails to generalize to arbitrary two-dimensional configurations. The most general model of this sort is Grossberg's Boundary Contour System / Feature Contour System (BCS / FCS) model (Grossberg 1985, 1988) which also involves a spatial derivative followed by a spatial integral, except that in Grossberg's model both operations are defined as local spatial operations in two dimensions rather than as analytical formulae in one dimension, and therefore generalizes to arbitrary two-dimensional inputs. Grossberg's model is summarized schematically in Figure 4 using as an example an input of a white square on a black background. The first stage performs a spatial derivative, calculated by convolution with center-surround receptive fields as described above, producing a contrast-sensitive edge representation. The processing then splits into two parallel streams. The BCS stream produces a sharpened contrast-insensitive edge representation, i.e. cells are active along edges in the input, as indicated by the bright outline square in the figure. The FCS processing stream begins initially as a copy of the contrast-sensitive edge image of the previous stage, but a spatial diffusion operation allows the darkness and brightness signals to spread spatially in all directions, except for the constraint that the diffusion is restricted by edges in the BCS image. In this case, the darkness is free to spread outwards from the outer boundary of the square, filling in a black background percept, while the brightness spreads inwards from the inner boundary of the square, filling in a white foreground percept, but the diffusing brightness and darkness signals cannot cross the boundary of the square.
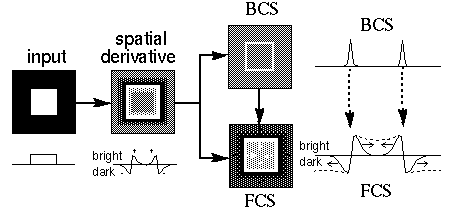
Schematic depiction of the processing stages of the BCS / FCS model, with intensity plots of a single scan line through the center of each image. At equilibrium the representation in the FCS becomes similar to the pattern at the input.
If the spatial derivative and spatial integration stages were mathematically exact, the integration stage would exactly invert the derivative stage, resulting in an exact copy of the input image. Due to a limited dynamic range of the representation however, (or a nonlinear saturation function applied to the spatial derivative image) large brightness steps are not registered in the same proportion as smaller brightness steps, which has the effect observed in the brightness contrast illusion, i.e. a gray patch on a dark background is restored to brighter than the original, while a gray patch on a white background is restored to darker than the original. This model therefore accounts for the brightness contrast effect in a manner that is isomorphic with the subjective percept, using mechanisms that involve local field-like interactions in a dynamic Gestalt relaxation model.
The purpose of all this processing, according to Grossberg, is to "discount the illuminant", or to implement the property of brightness constancy, whereby the intrinsic reflectance of an object is perceived despite the ambient illumination. This works because the spatial derivative image responds exclusively to local differences in illumination, and therefore any general cast over large regions of the image, or broad illumination gradient with sufficiently shallow slope, will fail to register in the spatial derivative image, and will therefore not be reconstructed in the FCS image. The information represented in the model therefore can be considered a "lightness" image, or image of perceived reflectance rather than of a brightness percept.
One of the most valuable contributions of Grossberg's BCS/FCS model is the clear distinction made in this model between a modal (or "visible" Grossberg's terminology) illusory contour and an amodal ("invisible") grouping percept. The word modal is used in the sense of brightness being a modality of perception (along with color, depth, motion, etc.) An amodal grouping percept such as the one shown in Figure 2 (B) creates a linear percept, i.e. a subject could easily trace the exact location of the contour joining the vertices in this figure, and yet no brightness difference is observed along that contour. In the Kanizsa figure shown in Figure 2 (A) on the other hand, an actual brightness difference is observed across the illusory edge, which is virtually indistinguishable from an actual luminance edge. An artist depicting the percept of the Kanizsa figure would have to use a different mix of white paint inside the triangle than outside it. In the BCS/FCS model both modal and amodal contours register in the boundary image of the BCS, but only modal contours register also on the FCS layer. The FCS representation therefore is a more low-level, direct representation of the brightness percept, whereas the BCS represents a higher level abstraction of a linear grouping percept which does not map directly to a brightness percept.
Lehar (1991) has proposed to rearrange the representational levels of the BCS/FCS model on the basis of the abstraction / reification distinction as shown in Figure 6. The lowest level of this model represents the surface brightness percept corresponding to the FCS layer; the next level up represents one level of abstraction to a contrast sensitive edge representation corresponding to the retinal image; the next level represents another level of abstraction to a contrast insensitive edge representation; the next level might represent a further abstraction such as the corners or vertices of the image, and so on upwards through higher levels of abstraction with the operations of abstraction, compression, and invariance being performed from level to level in a bottom-up manner, at the same time that the inverse operations of reification, decompression, and specification are being performed top-down from layer to layer, and further reification or figural completion is performed recurrently within each layer, completing the image in terms of the representation of the layer in question- boundary completion in edge representations and surface filling-in in surface representations. An interesting aspect of this model is that unlike conventional models of vision, the retinal input is not at the lowest level of the hierarchy, but enters the hierarchy mid-stream, i.e. the actual brightness percept is a top-down reification of the retinal input, which explains why the retinal image is an edge representation while the subjective percept is a surface representation. This makes perfect sense if the function of the visual system is to reconstruct a representation of the phenomenal world from the evidence provided by the senses, rather than to reconstruct the sensory input.
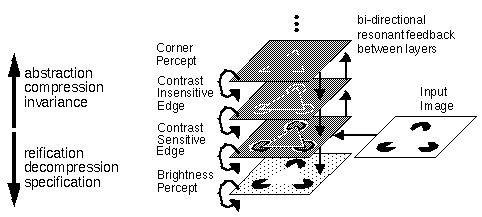
The Multi-Resonant Boundary Contour System (MRBCS) model (Lehar 1991) is similar to the BCS / FCS model except with the layers rearranged in terms of abstraction v.s. reification, i.e. lowest levels are more reified, while highest levels are more abstracted.
The operation of reification is by its nature underconstrained in that it requires information to be added to the abstracted representation. This additional information can be acquired from the local context through resonant feedback within each layer. Consider the input of a Kanizsa figure as depicted in Figure 6. Initially the contrast- sensitive edge representation (i.e. the retinal image) would register only the perimeter of each of the three pac- man features, without any representation of the illusory contour. Abstraction to the contrast-insensitive edge representation creates an image corresponding to the BCS image, again, initially representing only the outlines of the three inducing pac-man figures. A recurrent feedback within this boundary layer performs collinear boundary completion as in the BCS model, generating the illusory sides of the figure by collinear completion, as shown. In a top-down reification of these contrast-insensitive edges however, the information of contrast polarity must be added to them. In the absence of any evidence of the contrast polarity of these edges, the reification must remain indeterminate, i.e. opposite contrast polarities would be given equal weight, so that no contrast boundary would appear perceptually. In this case however the visible ends of the illusory edges do have a contrast polarity, so that contrast polarity can be filled in from the non-illusory ends to the illusory middle portions of the edge, as shown in the figure. Finally the next stage of reification completes the contrast-sensitive edge representation into a full surface brightness percept by a spatial diffusion within that layer as defined in the FCS model, producing the full Kanizsa illusion. This model illustrates how the concept of a hierarchical visual representation can be resolved with the Gestalt notion of parallel relaxation in a multi-stable dynamic system to produce a final percept which is most consistent with both the bottom-up input and the top-down influence. The model also shows how top-down influence can propagate from arbitrarily high levels in the representation in such a manner as to have a direct influence on the low-level perception at the lowest levels of the hierarchy, by a progressive translation of that top- down prime through successive intermediate representations, each of which fills-in the missing features represented at that level. This type of top-down reification is demonstrated by artists who convert an abstract invariant concept into a reified image of a particular instance of that concept viewed from a specific perspective, as well as by the operation of mental imagery. The hierarchical models proposed by Marr (1982) and Biederman (1987) are therefore in my view not wrong, but rather they are incomplete, representing only the bottom-up abstraction component of perception, without mention of the top-down reification component.
2.2 Brightness Contrast v.s. Brightness Assimilation
The phenomenon of brightness assimilation appears at first sight to be the exact opposite to brightness contrast. Figure 7 illustrates examples of brightness assimilation. All of the gray tones in this figure are the same, but the ones which appear adjacent to black features appear blacker, whereas the ones that appear adjacent to white features appear whiter. Unlike the brightness contrast effect therefore, the gray patches assimilate the character of the adjacent color, reducing rather than increasing the contrast between them. How can a single model explain both of these apparently opposite effects?
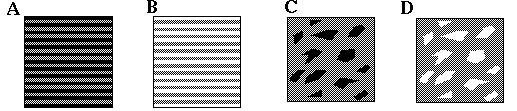
Brightness assimilation effect. All of the gray tones in theis figure are the same neutral gray, but the gray that appears adjacent to black appears blacker, while the gray adjacent to white appears whiter.
Kanizsa (1979) reports that the necessary conditions for the occurrence of brightness assimilation, as opposed to brightness contrast involves the degree of "compactness" of the inducing surface. That is, assimilation instead of contrast takes place when the inducing surface is "dispersed" (in the form of thin lines, small disks, or fragments) into the induced surface. I propose that the significance of this dispersion is that it changes the figure/ground relation between the fragments, making them appear as multiple components of a single larger form, rather than individual figures against a common ground. The nature of the diffusion of color between the fragments is reminiscent of the diffusion mechanism of the FCS model. I propose therefore that a mechanism like the BCS/ FCS model accounts for both the brightness contrast effect and the brightness assimilation effect, with the proviso that brightness contrast occurs between figure and ground, and serves to increase the contrast difference between figure and ground, whereas brightness assimilation occurs within the figure, or within the ground, serving to diminish contrast differences within the gestalt. In Figure 7 (A) and (B) for example each grid of alternating colors is seen as a single gestalt, and therefore brightness assimilation occurs within that gestalt, reducing the contrast between the stripes. In Figure 7 (C) and (D) the fragments appear to belong to each other, and thus they jointly define a single larger gestalt that unifies them, thereby spreading their perceptual properties by diffusion into the spaces between them. The operations of brightness contrast and brightness assimilation therefore can be seen as a visual analog of the phenomenon of categorical perception in speech, where subjects are exquisitely sensitive to phonemic differences across categorical boundaries, but remarkably insensitive to phonemic differences within categorical boundaries. In vision this might be expected to "cartoonize" the image, sharpening the edges between figure and ground, while smoothing or blurring features within the figure, or within the ground.
2.3 The Perception of Illumination
A number of phenomena of brightness perception cannot be explained using local ratio models, but indicate an important contribution from the perception of the illumination pattern of the scene. One example is the Gelb effect (Gelb 1929) where a black object under intense illumination can be made to appear white, but only as long as the illumination source is carefully concealed from the observer. As soon as the observer is made aware of the intense illumination source, the illusion disappears, and the object again appears black under bright illumination. Another problematical phenomenon for ratio models discussed by Gilchrist (1983) is the fact that a 90% reflectance square on a 30% reflectance background has the same figure/ground reflectance ratio as a 9% square on a 3% background. A ratio model such as the BCS / FCS would predict identical percepts in these cases, whereas in fact the percept is quite different, one appearing as a white square on a gray background while the other appears as a black square on a blacker background. Another condition which is problematical for the BCS / FCS model is the case where an illuminance edge is sharp, for example from a cast shadow, which would register in the spatial derivative stage, and thereby would not be discounted as an illuminant. Several researchers including Gilchrist (1983) and Kanizsa (1979) have suggested that no model of brightness perception can be complete without accounting for the perception of the illuminant. Generally this is taken to mean that there must be a cognitive appreciation of the contribution of the illuminant to the low-level perception of brightness. I propose on the other hand that the illuminant is perceived in the same low-level pre-attentive fashion as is surface brightness, and that local low-level interactions must be invoked to factor the image into reflectance and illuminance components.
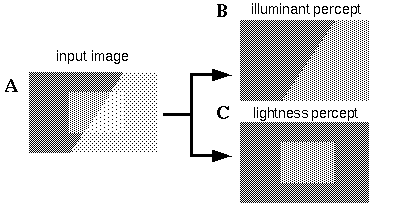
Perceptual scission of input image into two components of illumant percept and lightness percept.
Consider the pattern shown in Figure 8 (A). The nature of the intersections between the various patches of gray suggests a factorization into an illuminance percept as shown in Figure 8 (B), and a lightness, or reflectance percept as shown in Figure 8 (C). The fact that these two independent components of the image are perceived simultaneously in Figure 8 (A) suggests by isomorphism that the perceptual representation naturally separates the percept into these perceptual components. In other words, the principle of isomorphism suggests an explicit representation of the illuminance profile, which is experienced in the same pre-attentive low-level manner as the lightness or reflectance image. This dynamic factorization could be captured in a perceptual model with an architecture as shown in Figure 9. The brightness image bxy copies the brightness values directly from the input. This brightness information is then transferred point for point into either the illuminance image ixy or the lightness image lxy with the rule that the greater the brightness at a given point that is attributed to illuminance, the less that brightness can be attributed to surface lightness. This rule can be expressed as a dynamic interaction between nodes representing the three variables at each location as follows: activation of the brightness node, representing a bright percept at a point in the image, communicates activation to both the illuminance and the lightness nodes for the same image location. A mutually inhibitory connection between the illuminance and the lightness nodes ensures that both cannot simultaneously be highly active, but that they must distribute the activation from the brightness node between them proportionally- the more activation taken by the one, the less activation it allows in the other. This interaction expresses the conditions of factorization of the brightness image into its two components. This factorization of the brightness image into lightness and illuminance components is yet another example of reification in perception, and therefore these two extra layers would fit logically below the lowest level of the visual hierarchy depicted in Figure 6. Boundary completion and surface filling-in occuring separately within each of these layers would serve to unify the features in each, tending to produce simple regions with uniform lightness or illuminance, by the Gestalt principle of prägnanz.

A dynamic system model of the perceptual scission of brightness into an illuminance image and a lightness image.
I do not intend to develop the mathematical details of such a model here, but merely to suggest that the perception of the illuminant in this simple case could easily be represented as a low-level image in an isomorphic representation, and that it is conceivable that local interactions could be defined between these different representations which would result in the emergence of the proper factorization. Rather than developing the details of such a model, I would like to discuss where such modeling concepts can take us, and how this manner of approaching the problem holds promise for explaining some of the most troublesome aspects of visual perception which have not yielded to the more conventional approach to modeling perception.
The perception of three-dimensional form is a topic all of its own, and represents the most problematical component to the perception of lightness brightness and illuminance, and therefore one which has most readily been attributed to higher level cognition. Indeed in the conventional view of perception as embodied in models such as Marr's Vision (1982) and Biederman's Geon theory (1987) the three-dimensional spatial percept is the last to be computed, at the highest levels of abstraction, and these models contain no reified three-dimensional reconstruction of the perceived surface. I would argue on the other hand that the perception of three-dimensional form is a low level phenomenon, and represents yet another stage of reification of the two-dimensional input into a more complete and information-rich three-dimensional percept. Indeed there is growing psychophysical evidence for such a spatial reification of surfaces in perception (Anstis 1987, Brookes 1989, Collett 1985, Coren 1972, Mitchison 1993, Takeichi 1992).
3.1 An Underconstrained Problem
Consider the vertex shown in Figure 10 (A). The subjective percept of this stimulus is of a three-dimensional corner as suggested schematically in Figure 10 (C), although the percept is actually multistable, as it can also be seen as either a convex or a concave corner, or even as a flat "Y" shape in the plane of the page. Notice that in the three-dimensional percepts the lines in the figure appear to pull the white surface of the page into depth between the lines, producing a percept of three plane surfaces that meet at a corner. The principle of perceptual modeling would suggest that the task of a model of spatial perception is to explain this transformation from the two- dimensional input to a multistable three-dimensional percept, as suggested in Figure 10 (B), leaving to the neurophysiologists the task of explaining how the information evident in the percept of Figure 10 (C) might be represented in the brain. As soon as the problem is expressed in these terms, it becomes immediately manifest that this is a problem of reification, i.e. that information must be added to the information available in the input in order to produce the percept. Indeed, this is the inverse optics problem, which is an underconstrained problem since there are an infinite number of three-dimensional configurations that correspond to the single two- dimensional projection. Adelson (1992) expressed the nature of the inverse optics problem using a mechanical rod-and-rail analogy shown in Figure 11 (A). In this model three rods, representing the three edges in the visual input of Figure 10 (A), are constrained in two dimensions to the configuration seen in the input, but are free to slide in depth along four rails as shown in Figure 11 (A). Of course the rods must be free to expand and collapse in length, as suggested by the telescoping rod shown in Figure 11 (B), so that by sliding on the rails, the rods are free to take on any of the infinite three-dimensional configurations corresponding to the two-dimensional input of Figure 10 (A).
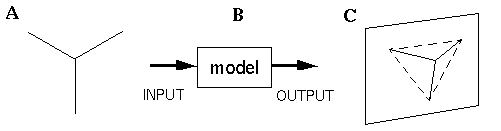
(A) A "Y" feature that appears as a corner in three dimensions. (B) The goal of perceptual modeling. (C) The information contained in the percept due to (A).
Underconstrained problems can be solved using a relaxation algorithm by applying the appropriate local constraints. For example the three lines always appear to meet at a single vertex, and the vertex tends to be one composed of mutually orthogonal edges. These constraints can be expressed in the rod and rail model by fixing the ends of the three rods to each other, and by applying spring forces at the vertex, as suggested in Figure 11 (C), which tend to hold the three rods at right angles to each other. This rod and rail model now defines a multi-stable dynamic system model of the percept of Figure 10 (A) which tends to pop into two stable states corresponding to the two predominant percepts of that figure. This model however is hard-wired for the visual input in Figure 11 (A) and does not generalize to arbitrary inputs.
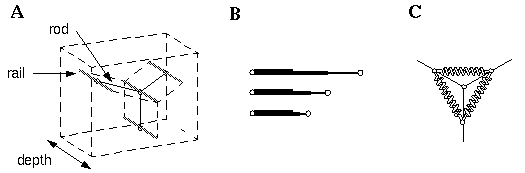
(A) Rod and rail model by Adelson (1992); the rods represent the three edges which are constrained by the rails to move only in depth. (B) Each rod must be free to contract and expand. (C) Dynamic constraint added to the system in the form of springs at the vertex between the three rods, which tends to hold them in a mutually orthogonal configuration.
3.2 A Gestalt Bubble Model
In order to develop a more general model of perception, we begin with a three-dimensional matrix of dynamic computational elements in a block as shown in Figure 12 (A). Each element in this block can be in one of two states, transparent or opaque, the latter representing the perception of an opaque surface at a particular location and depth. Elements in the opaque state take on a "surface orientation" value, and interact with adjacent elements in a coplanar manner, communicating excitatory activation to other elements within the plane of the local surface, and inhibition to local elements outside of their local plane, as suggested by the coplanarity interaction field in Figure 12 (C). If all of the elements in the block of perceptual tissue were initially assigned random values of transparent or opaque, with random local surface orientations for units in the opaque state, the local coplanarity constraint would cause local opaque elements to recruit neighboring elements in a coplanar configuration, tending at equilibrium to produce a single sheet or plane of active cells at a particular depth within the volume of the block, representing a perceived surface at that depth, as shown in Figure 12 (A). This kind of dynamic relaxation model is reminiscent of the soap bubble analogy proposed by the Gestaltists (Attneave 1982) as a model of perception. Like a soap bubble, the three-dimensional surface defined by a sheet of active units is free to bend and stretch within the solid volume of the representation, and its dynamic stiffness, or resistence to bending can be adjusted parametrically by varying the functional form of the local coplanarity function.
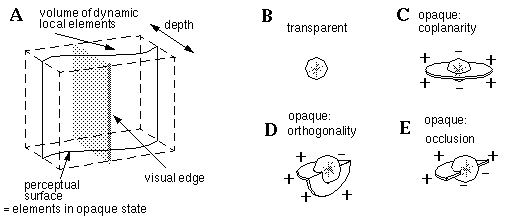
(A) The Gestalt Bubble model consisting of a block of dynamic local elements which can be in one of several states. (B) The transparent state, no neighborhood interactions. (C) The opaque coplanarity state which tends to complete smooth surfaces. (D) The opaque orthogonality state which tends to complete perceptual corners. (E) The opaque occlusion state which tends to complete surface edges.
A visual edge has the effect of producing a corner or crease in the perceived surface, as seen in Figure 10 (A). This can be expressed in the model as follows: a two-dimensional visual edge is projected on the front face of the perceptual block, from whence its influence propagates in depth through the volume of the perceptual block, as suggested by the light shading in Figure 12 (A), changing the dynamic behavior of elements in the field of influence which are in the opaque state from a coplanar interaction to an orthogonal, or corner interaction as shown by the local force field in Figure 12 (D). The corner of this force field would align parallel to the visual edge, but otherwise remain unconstrained in orientation except by local interaction with adjacent opaque units. Alternatively, a visual edge might denote occlusion, so a third possible state for opaque elements is the occlusion state, which represents a coplanarity interaction in one direction only, as suggested by the occlusion field in Figure 12 (E). In the presence of a visual edge therefore, a local element in the opaque state would have an equal probability of changing into either the orthogonality or occlusion state. Elements in the orthogonal state tend to promote orthogonality in elements which are in line with the perceived corner, while elements in the occlusion state promote occlusion in elements which are in line with the perceived occlusion. In other words a single edge will tend to become either a corner or an occlusion, although the whole edge may change state back and forth in a multistable manner. The presence of the visual edge in Figure 12 (A) therefore would tend to crease or break the perceived surface into one of the different possible configurations shown in Figure 13. (A) through (D). The presence of a pair of adjacent vertical edges in the input would result in the emergence of still more complex configurations of surfaces in depth from the same simple local interactions, as suggested in Figure 13 (E) through (F). The exact configuration selected by the system would depend not only on the local image region depicted in Figure 13, but on adjacent regions of the image, because the spatial state in any local region tends to propagate into adjacent regions by coplanar completion of surfaces, or collinear completion of corners or edges until the entire system attains a globally stable configuration, the most stable state being the one which resolves conflicting surface interpretations in the most natural, or lowest energy manner, by the Gestalt principle of prägnanz.
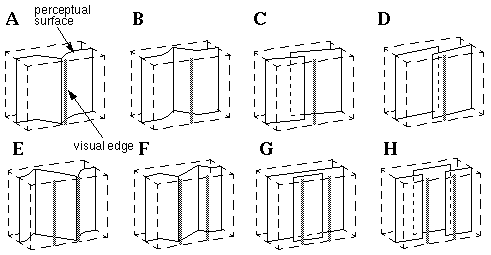
(A) through (D): Several possible stable states of the Gestalt bubble model in response to a single visual edge. (E) through (H): Several states of the same system in response to two adjacent vertical edges.
3.3 Properties of the Model
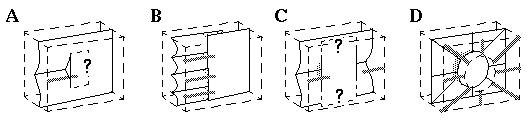
Collinear boundary completion, which is expressed in the BCS model as a collinear propagation of boundary signal, in this model becomes a physical process analogous to the propagation of a crack or fold in a physical medium. A visual edge which fades gradually would produce a physical crease in the perceptual mechanism as suggested in Figure 14 (A), which would tend to propagate outward beyond the visual edge. If two such edges were found in a collinear configuration, the perceptual surface would tend to crease or fold between them as suggested in Figure 14 (B).

(A) Boundary completion in the bubble model: A single line ending creates a crease in the perceptual surface. (B) Two line endings generate a crease joining them. (C) Closure: an enclosed contour breaks off a separate segment of perceptual surface as a figure in front of a ground. (D) Alternative response to a closed contour as a hole through to a surface further behind.
This model suggests an explanation for the Gestalt principle of closure, whereby an enclosed contour appears to produce a special perceptual phenomenon of a segmented figure in front of a background surface. In this model this percept of closure is explained isomorphically exactly as it appears, as shown in Figure 14 (C), where an enclosed contour is seen to break away a piece of the perceptual surface, completing the background surface amodally behind the occluding foreground figure. An alternative perceptual response to the same closed contour is depicted in Figure 14 (D), where the enclosed contour cuts a hole in the perceived surface, offering a view through to another more distant surface beyond, although this configuration offers less prägnanz, and therefore would require more supporting evidence from adjacent image regions.
A special condition occurs in this system in response to an abrupt line ending, which creates a local point of high stress in the perceptual surface, as suggested in Figure 15 (A). This tends to pull a local piece of the perceptual surface up away from the background, although the spatial bounds of this occluding surface remain largely undetermined by the action of a single isolated line ending. When multiple line endings occur in parallel however, their joint influence can pull away a complete piece of occluding perceptual surface as suggested in Figure 15 (B). When two abrupt line endings are presented opposite each other, they also tend to break away an occluding surface between them as shown in Figure 15 (C), and furthermore, they tend to propagate behind the occluding surface resulting in an amodal completion of the collinear edges behind the occluding surface. This model therefore explains the phenomenon of amodal completion in a manner which is isomorphic to the percept, i.e. the amodal line is both perceived, and perceived to be occluded by a foreground surface. Amodal completion together with the special condition of closure explains the emergence of the Ehrenstein illusion as shown in Figure 15 (D), again in a manner which is isomorphic to the subjective percept of this illusion.
(A) An abrupt line ending generates a local point of high stress that tends to break a piece of the perceived surface into the foreground. (B) Multiple aligned line endings break a surface into foreground and background. (C) Two abrupt line endings in collinear configuration complete amodally behind a foreground surface. (D) The Ehrenstein illusion by closure and amodal completion.
I have not defined the mathematics behind the dynamic interactions in this model, and indeed those interactions would of necessity be rather complex in order to achieve the results depicted in Figures 14 through 16. Indeed it remains to be shown whether such dynamics are definable in principle to achieve those results. In other words this model represents a hypothesis which remains to be tested for feasibility. What is important at this point however is that I have demonstrated how the perception of three-dimensional form can be considered as a low- level perceptual interaction rather than a high level cognitive inference, and can be designed to produce a fully spatial reification of the perceived surfaces. I have suggested how a model of spatial perception can embody the Gestalt principles of isomorphism and multistability in perception, using a Gestalt relaxation model inspired by the soap bubble analogy. In section 4 I will show how this type of model might be configured to respond also to dynamic constraints imposed by information about surface brightness, reflectance, and perceived illumination.
3.2 Bounding the Representation
The model I have presented so far represents an explicit volumetric or "voxel" (volume pixel) representation of external space. But Euclidean space is boundless, whereas the human skull is bounded. How can a boundless space be represented explicitly in a bounded representation? First of all, the depth dimension can be represented by a vergence measure, which maps the infinity of Euclidean distance into a finite bounded range, as shown in Figure 16 (A). This produces a representation reminiscent of museum dioramas, shown in Figure 16 (B), where objects in the foreground are represented in full depth, but the depth dimension gets increasingly compressed with distance from the viewer, eventually collapsing into a flat plane of the background. The depth dimension in this representation can be compressed relative to the other dimensions without violating the principle of isomorphism, resulting in a representation reminiscent of a bas-relief sculpture, as shown in Figure 16 (C). If however the depth dimension is quantized, for example into discrete depth layers as shown in Figure 16 (D), this now no longer corresponds to our subjective perception of depth, and therefore represents a violation of the principle of isomorphism.
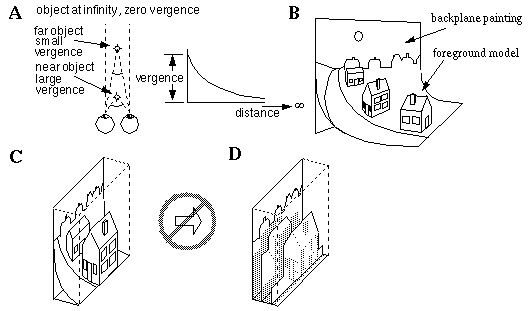
(A) A vergence representation maps infinite distance into a finite range. (B) This produces a mapping reminiscent of a museum diarama. (C) The depth scals can be compressed relative to the other two dimensions producing a representation reminiscent of a bas-releif sculpture. (D) If depth is further quantized into discrete layers, the representation is no longer isomorphic to the subjective percept of depth.
The other two dimensions of space can also be bounded by converting the x and y of Euclidean space into azimuth and elevation angles, producing an angle / angle / vergence representation as shown in Figure 17 (A). This structure now maps the infinity of external space into a finite bounded spherical coordinate system with the ecological advantage that the part of space most important for survival, i.e the space near the body, is represented at the highest spatial resolution, whereas the less important more distant parts of space are represented at lower resolution. All distances beyond a certain radial distance are mapped to the surface of the representation which corresponds to perceptual infinity. This too is isomorphic to our subjective experience of space, where the moon, stars, and distant mountains all appear as if pasted against the dome of the sky. The transformation from the infinite Cartesian grid in Figure 17 (B) to the angle / angle / vergence representation depicted in Figure 17 (C) actually represents a perspective transformation on the Cartesian grid- in other words the transformed space looks like a perspective view of the Cartesian grid when viewed from inside, with all parallel lines converging to a point in both directions. The significance of this observation is that by mapping space on a perspective- distorted grid, the distortion of perspective is inverted, in the same way that plotting log data on a log plot removes the logarithmic component of the data. Consider a perspective view of the world depicted in Figure 17 (D). If the distorted reference grid of Figure 17 (C) is used to measure lines and distances in Figure 17 (D), the bowed line of the road on which the man is walking is aligned with the bowed reference grid in the coordinate system, and therefore that line is perceived as being straight. Also the fact that the sides of the road appear locally parallel, and yet they also appear to meet at a point at the horizon both ahead and behind, is not a paradoxical observation in this representation because the reference grid has those same properties. Likewise the vertical walls of the houses in Figure 17 (D) bow outwards away from the observer, but in doing so they follow the curvature of the reference lines in the grid of Figure 17 (C), and are therefore perceived as being both straight, and vertical, since the vertical extensions of these curved lines meet the bounding surface of the perceptual sphere above and below. Since the curved lines in this spherical representation represent straight lines in external space, all of the spatial interactions discussed in the previous section, including the coplanar interactions, and collinear creasing of perceived surfaces, must follow the grain or curvature of collinearity defined in this distorted coordinate system. The distance scale encoded in the grid of Figure 17 (C) represents the regularly spaced Cartesian grid by a nonlinear collapsing grid whose intervals are spaced ever closer as they approach perceptual infinity, but nevertheless, represent equal intervals in external space. This nonlinear collapsing scale thereby provides an objective measure of distance in the perspective-distorted perceptual world. An interesting property of this representation which will be used in the next section, is that different points on the bounding surface of the spherical representation represent different directions in space, and all parallel lines which point in a particular direction in space converge in this representation to the point on the surface representing that direction.
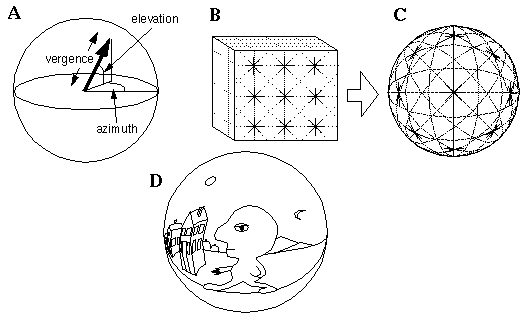
(A) An azimuth / elevation / vergence representation maps the infinity of three-dimensional Euclidean space into a finite spherical space. (B) The infinite Cartesian grid (section) showing lines of collinearity at every angle through every point. (C) The deformation of the Cartesian grid caused by the perspective transformation of the azimuth / elevation / vergence representation. (D) A view of a man walking down a road represented in the perspective distorted space.
Now that I have developed a structural representation of three-dimensional perceived space, I will show how the spatial nature of this representation allows for low-level spatial computations of lightness, brightness, and illuminance, which would be impossible in a more abstracted representation. Figure 18 (A) depicts a multistable percept that can be seen as either a convex corner, as shown in Figure 18 (B), or concave corner, as shown in Figure 18 (C) , or perhaps as two diamond shaped tiles in the plane of the page, as shown in Figure 18 (D). In an isomorphic model this change in perception between three stable states would be accompanied by a corresponding change in the state of the internal spatial representation. What is interesting in this percept is how the perception of the spatial structure is seen to influence the perception of the illuminant of the scene. When viewed as a convex corner the illuminant is seen to the left, whereas when viewed as a concave corner the illuminant is perceived to the right. When seen as two diamond shaped tiles the illuminant becomes irrelevant, because the difference in brightness between the two tiles is seen as a difference in reflectance rather than a difference in illumination. This example reveals the intimate connection between the perception of structure, surface lightness, and illuminant. How can these aspects of perception be added to our model of spatial perception?
(A) A tri-stable spatial percept with associated tri-stable illuminance percept. (B) through (D): the three percepts resulting from the stimulus in (A).
The principle of isomorphism suggests that we model the percept as it appears subjectively. I propose therefore a reverse ray-tracing algorithm to convert the spatial percept into a percept of the illumination profile. Consider the case when the figure is seen as a convex corner, as depicted in Figure 18 (B). The "sunny side" surface would propagate a percept of bright illuminant to the left, while the "shady side" surface would propagate a perception of dark illuminant to the right. When the spatial configuration of the figure reverses, as shown in Figure 18 (C), the percept of the illumination profile is also automatically reversed. In the case of the flat percept of two diamond shaped tiles depicted in Figure 18 (D), both surfaces project back to the same direction of illumination, and therefore their influences cancel. Since the difference in surface brightness can no longer be attributed to a difference in illumination, that difference must now be due to surface lightness, or perceived reflectance.
In the previous section on the distorted spherical representation, I mentioned that points on the surface of the perceptual sphere represent directions in space, and indeed the connectivity of the distorted representation is such that all parallel lines meet at a point on the bounding surface of the sphere. This architecture offers a means of calculating the perceived illumination from every direction in space based on the configuration of the perceived scene. Imagine that the pattern of collinearity represented in the reference grid depicted in Figure 17 (C) is designed to model the physical propagation of light through space. In other words any local element which is in the transparent state, when receiving a signal representing light from any direction, responds by passing that signal straight through the local element following the lines of collinearity defined in the perspective distorted space. This way light signals generated by a modeled light source will propagate along the curves in the representation so as to simulate the propagation of light along straight lines in Euclidean space. If a point on the surface of the perceptual sphere is designated as a light source, that light signal will propagate throughout the volume of the perceptual sphere as shown in Figure 19 (A). This model therefore is capable of modeling or simulating the illumination of a scene by a light source. Whenever the light signal encounters a perceived surface, i.e. elements in the opaque state, the elements representing that surface take on a surface illuminance value which is proportional to the total illumination striking that surface from any direction. A second variable of surface reflectance is also represented by every element in the opaque state, and the product of the perceived illumination and the perceived surface reflectance produces a percept of the brightness at that point on the perceived surface.
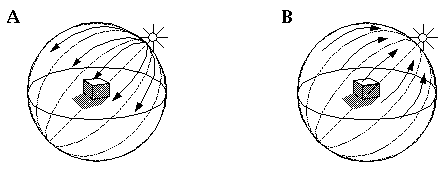
(A) A model of a perceived illumination source on the surface of the perceptual sphere propagates light signal throughout the volume of the perceptual sphere, illuminating all exposed opaque surfaces in that representation. (B) A reverse ray-tracing from every opaque surface in the space back to a percept of the illuminant apparently responsible for the observed illumination of the scene.
The ray tracing performed by this model can also operate in the reverse direction, taking the perceived surface brightness signal from every point in the scene, and propagating it backwards along the reverse light path to produce a percept of the illumination profile due to the scene. In the scene depicted in Figure 19 (B) for example, the large number of illuminated surfaces which are pointing upwards to the right produces by reverse ray-tracing a percept of a bright illuminant in that direction, while the shady surfaces in the same scene project a percept of dark illuminant in the opposite direction. In fact the whole scene produces a complete illuminance profile throughout the bounding surface of the perceptual sphere. The forward and reverse ray tracing calculations operate simultaneously and in parallel to produce by relaxation a single globally coherent percept of both the perceived scene and the illumination profile of that scene. This relaxation loop will become clear by stepping through an example.
Consider the visual input depicted in Figure 18 (A). This two-dimensional stimulus produces a three-dimensional percept as described in the section on the bubble model above. Let us consider the case of the percept of the convex corner depicted in Figure 18 (B). The points on the surface of this three-dimensional percept are represented by elements in the opaque state. Each opaque element has associated with it three values- a value for the observed surface brightness b, a value for reflectance or lightness l, and a value for local illuminance i, as shown in Figure 20, which depicts the three nodes corresponding to a single point on each of the two panels. As in the simpler brightness model depicted in Figure 9, the brightness value is recorded directly from the input, in this case registering a higher value for the brightness of the left panel than the right, i.e. b1 > b2. The brightness node sends activation to both the lightness node l and the illuminance node i at that same point in the surface, and a mutual inhibition between the lightness and illuminance nodes distributes the activation from b between l and i as described earlier, performing the factorization of brightness into lightness and illuminance components. Now since the corner percept defines a single gestalt, a three-dimensional variation of the FCS diffusion process is active within that gestalt, performing a brightness assimilation, or diffusing a percept of uniform reflectance throughout the two panels. This spatial diffusion occurs within the three-dimensional plane of opaque elements defining the two perceived surfaces of this figure, and propagates across the corner joining the two panels, resulting in a tendency for the lightness values to equalize, i.e. l1 = l2. Since the difference in brightness between the two panels cannot be accounted for by a difference in lightness, therefore each panel takes on a different value of local illuminance, the brighter panel experiencing greater local illuminance than the darker panel, i.e. i1 > i2. The local illuminance signal in turn propagates from each of the two surfaces of this percept, moving principally in a direction normal to the perceived surface, and arriving by way of intermediate transparent elements at the bounding surface of the perceptual sphere where the global illuminance nodes I1 and I2 register the perceived scene illumination in the directions normal to the perceived surfaces. Since the two surfaces point in different directions, the emerging percept of the illuminant profile will be of a bright illuminant to the left, and a darker illuminant to the right, i.e. I1 > I2. These illuminant values are registered by the activation of units on the bounding surface of the spherical representation. Now to follow the feedback loop in the opposite direction, the bright and dark illuminant percepts propagate bright and dark illuminance signal from the bounding surface of the perceptual sphere back to the two-panel corner at the center, where they strike the two panels in a manner that is consistent with the brightness percept, i.e. the brighter illuminant signal from I1 strikes normal to the brighter face, while the darker signal from I2 strikes the darker face. Since the values of global illuminance I1 and I2 match the local perceived illuminance i1 and i2, everything is consistent, and the system reaches a stable state.
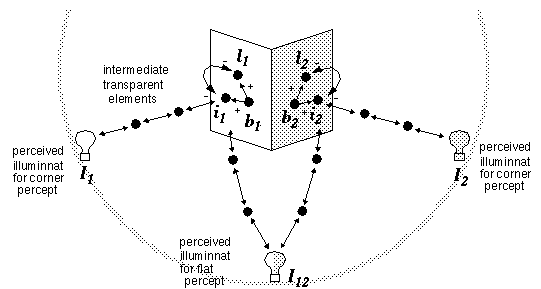
A dyanmic model of the interaction between brightness, lightness, illuminance and three- dimensional form in the Gestalt bubble model.
For contrast let us now consider the case of the percept where the two panels are seen as two diamond shaped tiles in the plane of the page, as shown in Figure 18 (D). Again we begin with the two-dimensional input producing a three-dimensional percept, this time of the flat percept depicted in Figure 18 (D). Again, these two features define a single gestalt, and therefore the system attempts to assign a uniform reflectance to the two tiles, by a spatial diffusion of reflectance signal within the gestalt, i.e. in Figure 20, l1 = l2. The difference in brightness between the two panels again results in a difference in illuminance for each panel, the bright panel registering a stronger illuminance than the darker panel, i.e. i1 > i2. This illuminance signal again propagates principally normal to the surfaces, except that this time both surfaces are facing the same direction in space, and therefore the brighter and darker illuminance signals are reverse ray-traced back to the same location on the surface of the perceptual sphere, labeled I12 in Figure 20, where they cancel, producing an illuminance signal of an intermediate illumination value. This global illuminance in turn gets propagated forward again from the surface of the sphere to the two-panel feature, where the uniform illuminance signal strikes both perceived surfaces with equal strength. In this case therefore there is a disconfirmation of the difference in illuminance between the two tiles, the brighter one registering less illumination than required to explain its brightness, and the darker one registering more illumination than required to explain its brightness, i.e. I12 < i1 but I12 > i2. This equation is not balanced, and therefore the original postulate of l1 = l2 represented by the assimilation can no longer hold. The inadequacy of the illuminant signal on the left side promotes an increase in the reflectance on that side, while the excess illuminant on the right side promotes a decrease in reflectance on that side, resulting in a new relation of l1 > l2. This disconfirms the process of assimilation between the two panels, and replaces it with a brightness contrast instead of brightness assimilation, resulting in a difference in lightness across the corner between the two panels. The process described above as a sequential back and forth between the center and periphery of the perceptual sphere should actually be imagined to emerge in parallel, i.e. the processes of brightness assimilation and brightness contrast emerge simultaneously at the edge between the two panels, but the one that receives more confirmatory evidence in the feedback from the periphery of the sphere will eventually suppress the other process.
The above description is somewhat heuristic, and many details remain to be worked out. Again, the purpose of this discussion is not to present a complete model of brightness perception, but merely to suggest an alternative low-level approach to the problem of perceptual modeling. This elaborate model at least offers an account for the phenomenon depicted in Figure 21. In this figure all of the blocks except for one exhibit a dark face pointing to the right. This accumulation of evidence from so many surfaces produces a strong percept of a dark illuminant from that direction. The single white face pointing in that direction therefore is presumed to be self-luminant, because no amount of surface reflectance can account for such a bright reflection from such a dark direction. Notice how the anomalously bright face appears brighter than the white top of the block, despite the fact that both of these whites are actually the same white of the unprinted page.

An illusory phenomenon explained by the Gestalt bubble model. The anomalously bright face is due to the fact that all other cubic faces pointing in that direction register a dark illuminant from that direction.
I have presented in the briefest outline sketch, the most fantastically elaborate model of spatial perception. Since this model represents so great a departure from the conventional approach to modeling perception, the intention has been not so much to elaborate specific details of the model, but rather to present the overall design methodology, to present a modern computational formulation of the principles embodied in the Gestalt theories. The power of the resulting model, or modeling approach, is not in its ability to account for any particular perceptual phenomenon, because models have been proposed to account for many of these phenomena independently, but rather to offer an account for a great number of fundamentally diverse perceptual phenomena by way of a single modeling strategy. In this section therefore I will touch on a few of the diverse areas of perception where this modeling approach promises to afford a solution.
5.1 Transparency
In the system described above, the dynamic local elements can be in one of two states, transparent or opaque. If we allow an intermediate state of semi-transparent, then all of the phenomena of perceptual transparency can be added to the repertory of phenomena explained by this model. The biggest difficulty with transparency has been to explain the complexity of the observed psychophysical phenomena using the simplistic architectures allowed by the neural modeling approach. In particular, how is one to encode whether a particular percept is transparent or opaque? How does the visual system check for the topological, figural, and chromatic conditions for transparency? While I do not propose a solution to these issues, I submit that the solution will be easier to find by allowing the perceptual computations to occur in a fully spatial context. For example Figure 22 (A) shows an example of perceptual transparency, which produces a percept like that shown in Figure 22 (B), or perhaps Figure 22 (C). An alternative percept of four separate pieces as shown in Figure 22 (D) is generally not perceived. The Gestalt bubble model would suggest an emergence of the percept something like this: initially all of the edges register separately, producing a percept of four separate pieces as suggested in Figure 22 (D). Boundary completion between these components, as well as the principle of prägnanz operating on the geometrical forms, would tend to make the halves of the circle coalesce into a single gestalt. The horizontal divider of the circle however is exactly aligned with an edge of the rectangle, which would tend to make that edge coalesce with the rectangle producing a rectangular gestalt. This produces a conflict however because the lower semi-circle belongs to both the circle and the rectangle. The conflict can be resolved by a scission of the semicircle into two separate layers. Assimilative diffusion within the circular gestalt would attempt to assign a uniform lightness to both halves, despite the difference in brightness. Again this conflict can be resolved by assigning a semi-transparency to the circle, which would be free to diffuse throughout the gestalt, resulting in greater prägnanz. Psychophysical evidence for this kind of interaction between transparency and perceptual grouping has been reported by Watanabe (1992)
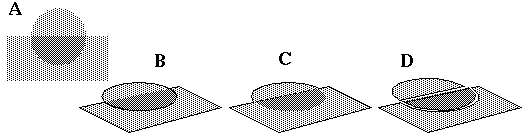
(A) An example of percetual transparency. (B) and (C) possible perceptual interpretations of (A). (D) Another possible percept of separate components of (A). A Gestalt Bubble Model of the Interaction of Lightness, Brightness, and Form Perception
Again this description is merely heuristic, but the principles behind this explanation are clear: that the spatial and chromatic ambiguities of the configuration can best be resolved in a fully spatial context rather than in some abstracted representation; that the Gestalt principles must be encoded in the form of simple local dynamic interactions which result in global perceptual influences; that the chromatic conditions for transparency are modeled by creating a physical analogy of the mechanism of transparent transduction.
5.2 Neon Color Spreading
The phenomenon of neon color spreading has been attributed to a transparency effect where the illusory occluding figure is seen as a transparent overlay over the intersection of two orthogonal lines. Indeed Bressan (1993) has shown a connection between neon color spreading and color assimilation. This phenomenon is also most easily explained in a fully spatial context. Figure 23 (A) represents the response of the Gestalt bubble model to a four line Ehrenstein illusion, producing, by amodal completion and closure, the percept of an occluding circle over the amodally perceived intersection. If the cross is completed in red through the occluder, the intersection is seen as if through a semi-transparent occluder which appears to filter the black lines of the cross to a red color, as shown in Figure 23 (B), where the light gray tone represents red. At first sight this might appear to represent a violation of the physics of filtering, because no colored filter can transform black lines into red, because black contains no component of red. This percept is best understood however by considering the filter not as an optically perfect red filter, but rather as a milky reddish color, like the color of milky water containing red dye. This would act not simply as a filter, but would also be able to reflect ambient light, giving it a red tint. With sufficient transparency this red tint would be virtually invisible over a white background, because the delicate tint would be swamped by the more intense white light from behind. Over the black lines of the cross on the other hand, the red tint in the filter would become apparent, just as the dust on a dirty window is most easily seen when viewed against a dark background. To model this effect therefore, transparency must be defined not as a perfect optical filter, but rather like a regular reflecting surface which is also semi-transparent, somewhat like an opaque red paint applied to a glass surface in a fine misty spray. If the occluding surface is given this character by the perceptual system, assimilation would tend to diffuse this color evenly throughout the occluding gestalt, thus explaining the ghostly tint of color which appears in the neon color effect, as suggested in Figure 23 (B). Again, the point is that the heuristic description of the phenomenon corresponding to the subjective experience of this illusion is, by the principle of isomorphism, an accurate clue to the nature of the internal representation of the effect, so models of the phenomenon of neon color spreading should, in my view, be expressed in fully spatial terms. Evidence for the close interaction between transparency, depth perception, subjective contours, and neon color spreading has been measured psychophysically by Nakayama (1990).
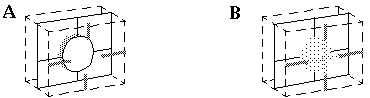
(A) The four line Ehrenstein illusion modeled by closure and amodal completion behind an occluding surface. (B) The neon color spreading effect explained as color assimilation within a semi- transparent occluding surface.
5.2 Shape from Shading
The phenomenon of shape from shading is another example of an underconstrained problem which however offers a valuable clue to the configuration of the perceived object. Formal attempts to express the problem of shape from shading in rigorous mathematical terms have only served to highlight the multiple uncertainties inherent in the problem. The Gestalt bubble model on the other hand offers a simple Gestalt solution to this problem. Figure 24 (A) illustrates an example of shape from shading. Since this figure is seen as a unified gestalt, assimilative diffusion would tend to assign uniform reflectance to the figure, so that any brightness variations would tend to be ascribed to differences in local illumination, and thereby, to differences in surface orientation. Given that the global illumination profile is known, this would have a tendency to "bulge" the perceived surface inwards or outwards at the points where the brightness varies, especially when it varies in a pairwise manner as shown in Figure 24 (A), i.e. where bright patches are balanced by dark patches, suggesting a bulge with both sunny and shady sides. By feedback, as the percept in Figure 24 (A) emerges, it in turn reinforces the percept of the illumination profile. The general principle in the Gestalt bubble model which simplifies these calculations is the property that the complex interaction between light and spatial form are unraveled by replicating the character of those interactions in a full spatial analog of the interaction of the spatial percept and its illuminant.
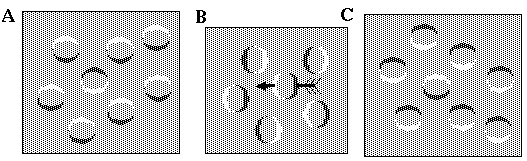
(A) Shape from shading produces a percept of concave and convex dimples. (B) In case of ambiguous illuminant, a single disambiguating cue determines a global illuminant direction, which in turn disambiguates the rest of the figure. (C) This figure is a vertically flipped version of (A), showing that perception assumes an illuminant from above.
If the illumination profile is not known in advance, then there remains a residual ambiguity about whether a feature is concave or convex. Since the bubble model integrates clues from a variety of modalities, a single clue in any modality is sufficient to disambiguate the entire percept. An example is seen in Figure 24 (B) where the arrow piercing one of the features marks that feature as a convex bulge rather than a concave dimple. This in turn constrains the illuminant to be perceived from the left, and that in turn constrains the perception of all of the other features in depth.
The bubble model even offers an explanation for the phenomenon that the illuminant tends to be expected from above. This is seen in the difference between Figure 24 (A) and Figure 24 (C), which are identical except that one is flipped vertically relative to the other. This inversion is seen however to convert concave dimples to convex ones, and vice versa. This can be explained in the Gestalt bubble model by a certain hard-wired bias in the perceptual sphere, that in the absence of contradictory evidence, the top of the perceptual sphere possesses a higher baseline illuminance level than the bottom.
5.3 Shadow Perception
The perception of shadow is related to shape from shading, and offers another valuable clue to the perception of both spatial configuration, and of the configuration of the illuminant. As before, the perceptual calculation of shadows in the Gestalt bubble model occurs by replication of the spatial properties of light propagation and of the perceived three-dimensional form. This naturally accounts for both attached shadows, as in shape from shading, but also cast shadows, since the perceptual mechanism replicates the blockage of light by an opaque object, and thus anticipates the appearance of a shadow cast by the object. This reasoning extends even to the perception of height due to a fully detached shadow, as shown in Figure 25 (A) which would also emerge as a natural property of the Gestalt bubble model, as suggested in Figure 25 (B).
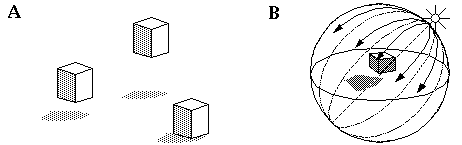
(A) Perceptual clue of height from a fully detached shadow. (B) This effect too is replicated by the Gestalt bubble model.
I have presented a rough outline sketch of a model of perception inspired by the Gestalt principles of global emergent properties from local interactions in a multi-stable system, whose equilibrium state can be influenced by forces in any of its component modules. I have shown how the principle of isomorphism suggests a perceptual modeling approach, which in turn reveals the presence in perception of a fully spatial reification stage, as well as multiple levels of abstraction which are perceived simultaneously to the reified percept. There are many issues that remain to be resolved. Where would such a representation reside in the brain? How would specific cells in the brain be able to respond meaningfully to the transient spatial patterns of activity which are not anchored to a particular tissue, but move freely through the volume of tissue? These objections were raised in response to Köhler's field theory of perception, for if the spatial pattern of activation representing a spatial percept is free to move about relative to the tissue of the brain, how can perception be ultimately connected to behavior? For presumably at some level, motor control must be triggered by the firing of some brain-anchored cells, and therefore the transient perceptual patterns must be able to trigger these brain-anchored cells. On the other hand, the fact that my percept of the external world remains solid and fixed as I rotate my head, suggests that the percept is anchored to the world, rather than to my head, and therefore that property should be expressed in a perceptual model. Lehar (1994) has proposed a solution to the anchoring problem by a harmonic resonance representation, or a pattern of standing waves to represent spatial patterns of activation in the brain, each transient standing wave pattern being associated with a brain-anchored cell by frequency coupling. These are important neural modeling issues which must yet be resolved. If the model accurately reflects the nature of the subjective experience of the percept, and offers a quantatitive isomorphic representation which corresponds to the subjective experience, then the model is unassailable as a perceptual model, even if its neurophysiological correlate remains to be identified.
7 Conclusion
The scientific approach to modeling complex physical systems has always been to break the problem into manageable pieces and model the pieces individually. In psychophysics this means measuring simple aspects of perception, and proposing models to account for the measured properties. There is always a danger in this method of approach because the measured complexity of any perceptual process is always limited by the complexity of the experiment which measures it. When the experiments performed are excessively simple, the results suggest correspondingly simple models to account for the data. The danger is that theorists take such simple models as representative of actual processes occurring in the brain. This was the mistake made by the Behaviorists who performed simplistic behavioral experiments which could then be explained by simplistic models of behavior. The Gestaltists approached the problem from the opposite tack, measuring and characterizing the most bizarre and paradoxical perceptual phenomena which defied explanation by simplistic models. As a result however the Gestaltists never produced quantitative models to account for the observed phenomena.
In recent decades the field of neural modeling has slipped into a condition reminiscent of the Behaviorist movement, with emphasis on modeling the results of simplistic single-cell recordings. Köhler himself warned that the point-like measurements from fixed brain locations would by their very nature preclude discovery of larger field-like processes, such as those suggested by the Gestalt phenomena. As a final test of the veracity of any theory of perception, the principle of isomorphism suggests that the subjective conscious experience should be the final guide as to whether our models are on the right track. When we find, as is the case today, a growing disparity between our models of neurophysiological processes and the observed properties of conscious perception, it is a sign that there are serious problems with our models of the brain. Until a better understanding of neurophysiological principles and mechanisms emerges therefore, a safer approach would be to restrict ourselves to perceptual modeling, as opposed to neural modeling, in order to characterize the information encoded in perception, rather than the neurophysiological mechanism by which that encoding is subserved. This will liberate our models from the limitations of current neurophysiological understanding, and allow our models to serve as a repository for accumulating and condensing in a meaningful manner the ever growing bulk of psychophysical evidence.
Acknowledgements
Supported in part by grant EY05957 from the NIH, and a grant from Hewlett Packard Co.
References
Adelson E, 1993 "Perceptual Organization and the Judgement of Brightness" Science 262 2042-2044
Adelson E, 1992 Lecture in Ennio Mingolla's class, Boston University
Anstis S, Howard I, 1978 "A Craik-O'Brien-Cornsweet Illusion for Visual Depth" Vision Research 18 213-217
Arend L, 1973 "Spatial differential and integral operations in human vision: Implications of stabilized retinal image fading" Psychological Review 80 374-395
Attneave F, 1954 "Some Informational Aspects of Visual Perception" Psychology Reviews 61 183-193
Attneave F, 1971 "Multistability in Perception" Scientific American December
Attneave F, 1982 "Prägnanz and soap bubble systems: a theoretical exploration" in Organization and Represen- tation in Perception Ed J Beck (Hillsdale NJ, Erlbaum)
Biederman I, 1987 "Recognition-by-Components: A Theory of Human Image Understanding Psychological Review 94 115-147
Bressan P, 1993 "Neon colour spreading with and without its figural prerequisites" Perception 22 353-361
Brookes A, Stevens K, 1989 "The analogy between stereo depth and brightness" Perception 18 601-614
Collett T, 1985 "Extrapolating and Interpolating Surfaces in Depth" Proc. R. Soc. Lond. B 224 43-56
Coren S, 1972 "Subjective Contours and Apparent Depth" Psychological Review 79 359-367
Dennett D, 1991 "Consciousness Explained" (Boston, Little Brown & Co.)
Eckhorn R, Bauer R, Jordan W, Brosch M, Kruse W, Munk M, Reitboeck J, 1988 "Coherent Oscillations: A Mechanism of Feature Linking in the Visual Cortex?" Biol. Cybern. 60 121-130.
Gelb A, 1929 "Die `Farbenkonstanz' der Sehdinge" Handbuch der normalen und pathologische physiologie 12 549-678
Gilchrist A, 1977 "Perceived lightness depends on perceived spatial arrangement" Science 195 185-187
Gilchrist A, Delman S, Jacobsen A, 1983 "The classification and integration of edges as critical to the perception of reflectance and illumination" Perception & Psychophysics 33 425-436
Grossberg S, Mingolla E, 1985 "Neural Dynamics of Form Perception: Boundary Completion, Illusory Figures, and Neon Color Spreading" Psychological Review 92 173-211
Grossberg S, (1987a) "Cortical dynamics of three-dimensional form, color and brightness perception. I. Monoc- ular theory. Perception & Psychophysics 41 87-116
Grossberg S, (1987b) "Cortical dynamics of three-dimensional form, color and brightness perception. II. Binoc- ular theory. Perception & Psychophysics 41 117-158
Grossberg S, Todorovic D, 1988 "Neural Dynamics of 1-D and 2-D Brightness Perception: A Unified Model of Classical and Recent Phenomena" Perception and Psychophysics 43, 241-277
Hubel D, 1988 "Eye, Brain, and Vision" (New York, Scientific American Library)
Kanizsa G, 1979 "Organization in Vision" (New York, Praeger)
Kennedy J, 1987 "Lo, Perception Abhors Not a Contradiction" In The Perception of Illusory Contours, Ed Petry S. & Meyer, G. E. (New York, Springer Verlag) 40-49.
Knill D, Kersten D, 1991 "Apparent surface curvature affects lightness perception" Nature 351 228-230
Koenderink J, Van Doorn A, 1976 "The singularities of the visual mapping" Biological Cybernetics 24, 51-59
Koenderink J, Van Doorn A, 1980 "Photometric invariants related to solid shape" Optica Acta 27 981-996
Koenderink J, Van Doorn A, 1982 "The shape of smooth objects and the way contours end" Perception 11 129- 137
Köhler W, 1947 "Gestalt Psychology" (New York, Liveright)
Land E, 1977 "Retinex theory of color vision" Scientific American 237 108-128
Lehar S, Worth A, 1991 "Multi-resonant boundary contour system" University, Center for Adaptive Systems technical report CAS/CNS-TR-91-017
Lehar S, 1994 "Directed diffusion and orientational harmonics: long range boundary completion through short range interactions" PhD thesis Boston University.
Marr D, 1982 "Vision" (New York, W. H. Freeman)
Mitchison G, 1993 "The neural representation of stereoscopic depth contrast" Perception 22 1415-1426
Nakayama K, Shimojo S, Ramachandran V, 1990 "Transparency: relation to depth, subjective contours, lumi- nance, and neon color spreading" Perception 19 497-513
Rensink R, O'Regan J, Clark J, 1995 "Image flicker is as good as saccades in making large scene changes invisi- ble" Perception (suppl.) 24: 26-27.
Takeichi H, Watanabe T, Shimojo S, 1992 "Illusory occluding contours and surface formation by depth propaga- tion" Perception 21 177-184
Todd J, Reichel F, 1989 "Ordinal structure in the visual perception and cognition of smoothly curved surfaces" Psychological Review 96 643-657
Watanabe T, Cavanagh P, 1992 "The role of transparency in perceptual grouping and pattern recognition" Per- ception 21 133-139